Table of Contents
Project OBJREP

Project OBJREP (an acronym for Object Repertory) aims at resolving a problem of effective materia medica knowledge representation that would be both comprehensive and easy to use.
Existing repertories, both modern and historical, suffer from incurable problems inherent to the sole principle on which an idea of repertory is based – that of a generalized index of symptoms.
Object Repertory would allow a huge and extraordinary leap in homeopathic treatment, as it uses a different paradigm that allows both a precise knowledge representation (as recorded in materia medicae) combined with an ease of use usually expected from a repertory.
The result of the project would be a database storing materia medica texts as an interconnected net of objects linked to a general homeopathic ontology. The database will be available to developers for incorporation into their (homeopathic) software.
This project is a part of Legatum Homeopathicum effort. Please also have a look at other projects we are working on.
Why we need Object Repertory
Throughout its history, homepathy has accumulated a great amount of knowledge about medicinal properties of various substances -– ranging tens of thousands of pages. This knowledge is the basis of homeopathic prescribing, providing indications and characteristics for homeopathic remedy selection. Unfortunately, this knowledge remains largely unused as there are no effective tools (to date) that would make this massive amount of knowledge accessible to a homeopath.
The existing repertories help to make homeopathic practice faster, but they all are
- lacking sufficient detail and overly generalizing, with important indications being unrecoverably lost in the process
- incomplete, even when it comes to including the early and important homeopathic materia medicae
- lacking a direct link to original symptoms, which could be used for understanding the context and details of that particular symptom
- lacking a systematic and VERIFIABLE process of rubric creation and remedy addition
To demonstrate those problems, let's take the an example symptom
“Fine stitching in the left temple with red halo around objects and a feeling as if he was in a strange place, although he is in his own bed, in the rainy morning after waking up and remembering the grievous occurrences of the past day.”
In a standard repertory, the remedy that presents the above symptom could be included in many standard rubrics, such as
Head, pain, stitching, temples
Head, pain, stitching, temples, left
Head, pain, temples
Head, pain, temples, left
Head, pain, temples, morning
Head, pain, temples, morning, waking, after
Mind, confusion of mind, morning
Vision, red, halo
Of course, there are many more combinations that could be created, such as
Mind, confusion of mind, headache, with
Head, pain, remembering past occurrences
Head, pain, bed, in
Head, pain, temples, remembering past occurrences
Vision, red, halo, headache, with
As should be clear, a great many more rubrics could be created (by combining various components and conditions of the original symptom), but the process involves many possible combinations, so in the end, only those rubrics are created which the author of the repertory deems fit. Given the nature of the rubrics and the process, the errors in adding remedies to their respective rubrics are inevitable.
Needless to say, the overall idea of the symptom is mangled to death even if we somehow managed to include the remedy in all the possible rubrics. Based on the repertorization, we could be induced to prescribe the remedy for someone experiencing a stitching pain in the temples, but reading the original symptom, that would hardly be a good idea, given all the other conditions (morning, rain, after waking, remembering unpleasant things) and special concomitant symptoms present (red halo, confusion with regards to place) -– unless they would be present, of course.
Constantine Hering, one of the great homeopaths of past times, was well aware of this and his “Analytical repertory of the symptoms of mind” involves all kinds of details (mostly quoting directly from materia medica) which, unfortunately, resulted in a book that simplifies the search for a remedy only very slightly and is more similar to using materia medica than a repertory as we know it today. Most rubrics contain only one or two remedies, the symptoms are quite difficult to locate, the rubrics, however, are very characteristic. (see excerpt below)

Object Repertory concept
A paradigm of object repertory creation considers iterative parsing of the sentences from the data source (materia medica, provings etc.) into basic categories and components and linking these to their respective ontological points. By ontological points we mean components of an ontological net (see Ontology ), which is a connected net of meanings representing various ontological relationships.
Ontology
An example below presents a very basic sketch of anatomical ontological net
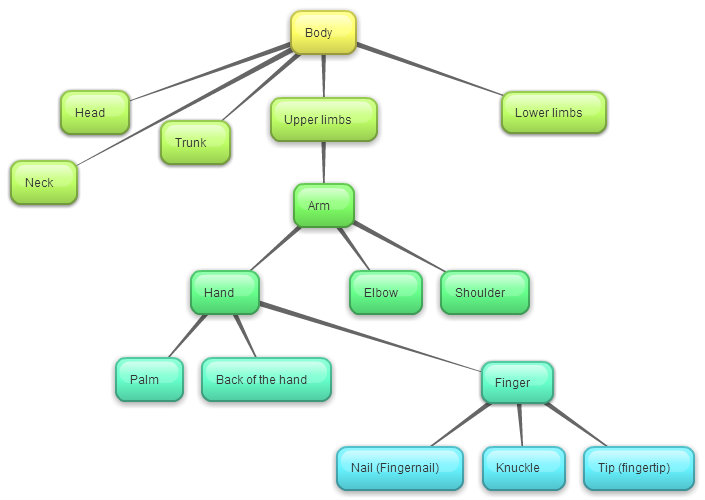
For practical purposes of knowledge representation, a more detailed net would be necessary, such as presented below.

Connecting symptoms to ontology
For the purpose of illustrating the process of mapping sentences to ontological net, let's use the same symptom as given previously:
“Fine stitching in the left temple with red halo around objects and a feeling as if he was in a strange place, although he is in his own bed, in the rainy morning after waking up and remembering the grievous occurrences of the past day.”
The process of mapping a symptom to the ontological net consists of the following steps:
- Separating the sentence into individual components representing separate states and assigning them to either SYMPTOMS or CONDITIONS domain. SYMPTOM domain denotes actual body/mind phenomena while CONDITIONS domain denotes accompanying conditions of the phenomena.
- Mapping the basic components of each SYMPTOM state and each CONDITIONS state, according to the categorization give below.
- Separating each basic component into distinct semantic units and mapping these to their respective ontological points of the ontological net
Categorization of the basic components
This is a preliminary categorization and is subject to modifications:
- Sensations within the person
- Objective (observable with five senses by an independent observer)
- Subjective (observed by the subject, not verifiable by an independent observer)
- Pertaining to body
- Pertaining to mind
- Pertaining to vision
- Pertaining to hearing
- Pertaining to smell
- Pertaining to taste
- Location
- Time
- Phenomena
- Modality
- Intensity
- Color
- Other attribute / modifier
- Logical AND operator
- Logical OR operator
Processing of the example sentence
Units in the SYMPTOMS domain:
Superscript provides categorization assignment.
- fine Intensity stitching Sensations / Subjective / Bodily in the left temple Location
- red halo around objects Sensations / Subjective / Visual
- feeling as if he was in a strange place Sensations / Subjective / Mind
Units in the CONDITIONS domain:
- he is in his own bed Location
- in the rainy Phenomena morning Time
- after waking up Phenomena
- remembering the grievous occurrences of the past day Phenomena
The image below provides a visual representation of the process.
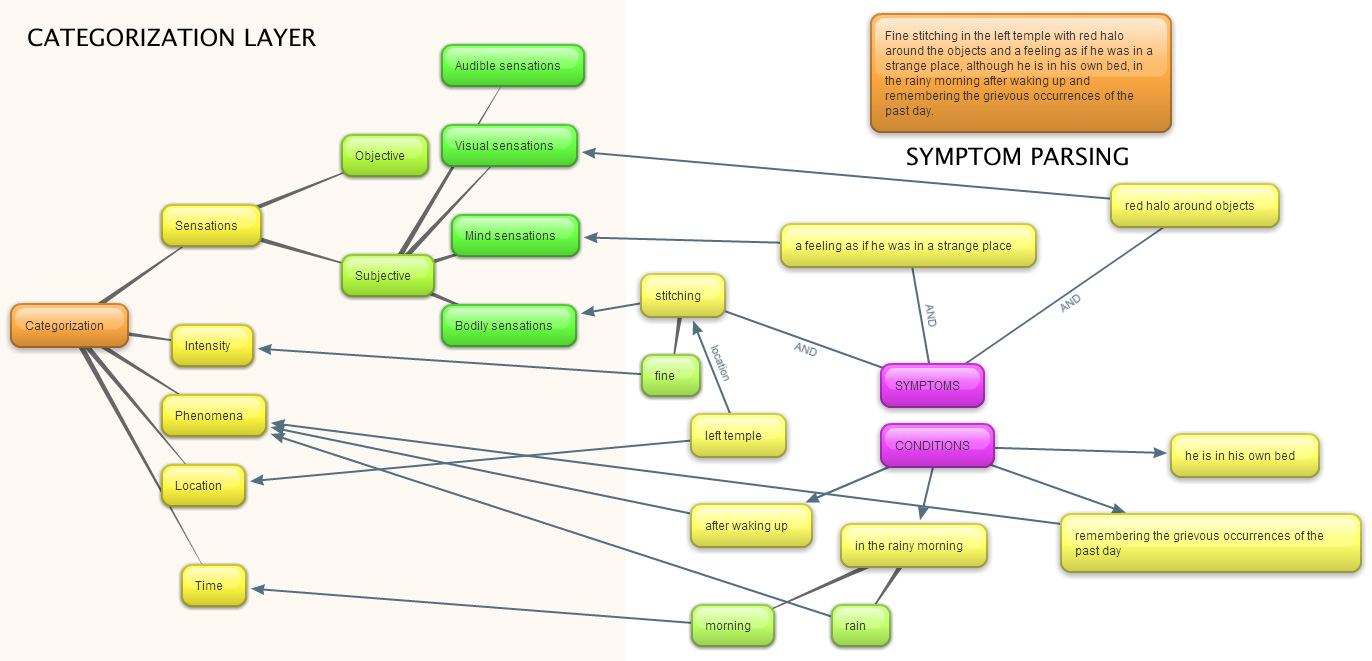
As a final step of the process, each semantic unit is linked to its respective ontological point, such as:
fine = mild; having low intensity
stitching = a series of sharp painful sensations as if produced by a pointed object
temple = the flat area on either side of the forehead
etc.
The advantages of Object Repertory compared to traditional repertories
The Object Repertory solves all the ailments of traditional repertories mentioned earlier:
- The information is always stored in the highest possible detail and the ontological net provides all kinds of generalization and conceptual views that could be desired. If other concepts are deemed necessary, the modification is performed in the ontological net, without the need to return to the original symptom.
- When recording sentences into object repertory, we can proceed one by one and assure the completeness of the job, which can be verified. There are no rubrics to miss as there are no rubrics.
- There is always a direct link to the original symptom.
- The process is systematic and verifiable, the possible errors can be spotted by ordinary users (of a software utilizing object repertory) and easily corrected.
In addition, the ontological net and the manner in which the symptoms are stored allows for use of artificial intelligence, data mining and expert systems algorithms which could greatly facilitate homeopath's job by suggesting specific questions to be asked, evaluating and justifying the selection of remedies and more.
Using Object Repertory
To have a better idea how Object Repertory would be used in practice, please read this article.
Creating Object Repertory
The process of implementation of object repertory can be divided into several phases:
- Developing software (ONTSOFT) for basic ontology net (ONTNET) creation.
- Creating a homeopathy-specific ontology net using ONTSOFT and by importing and reusing related free / open source ontologies.
- Selecting and preparing source texts (TEXTBASE) for mapping to ONTNET.
- Further developing ONTSOFT to support mapping of TEXTBASE (sentence by sentence) to ONTNET utilizing collaborative effort (crowdsourcing).
- Mapping TEXTBASE to ONTNET using collaborative effort, possibly with help of advanced algorithms (neural networks, statistical methods etc.).
- Optional: Further development of ONTNET.
Phase 3 may run in parallel to other phases, phase 2 may run in parallel to phase 4, phase 6 parallel to phase 5, as shown in the diagram below.

Phase 1: Creating ONTSOFT
ONTSOFT user interface and its use would be very similar to existing mindmapping / brainstorming / diagramming tools, such as bubbl.us used to create diagrams in this presentation. The difference would be in the use of data, enhanced classes, relationships, rules management and other functions necessary to create an ontology rather than a generalized mindmap.
While a general mindmapping / brainstorming tool would present generic connection among the nodes (which can be interpreted as seen fit), ONTSOFT would present specific classes of connections, for example PART OF connection (“finger” is PART OF “hand”), KIND OF connection (“index finger” is KIND OF “finger”).
ONTSOFT is planned as an online tool allowing collaborative effort, with user groups rights management and access restrictions. The data will be stored in a standard relational database server.
Potential investor could benefit from this software in various ways, as it would be possible to use it outside of the scope of this project, if interested. Possible utilization of ONTSOFT outside of scope of this project:
- general mindmap and brainstorming tool
- diagramming / process modeling and analysis tool
- creation of different domain-specific ontologies
- providing the above tools as either a free (enhancing PR image) or commercial service (revenue)
Estimated duration of Phase 1: 4 – 6 months
Estimated total costs of Phase 1: 15 000 – 20 000 EUR
Phase 2: Creating ONTNET
Creating ONTNET is the next major step in the process of creating the object repertory. A decent amount of work that can be utilized for creating the basic structure has already been done in the synonyms database of Mercurius homeopathic software which will kindly donate this work for the purposes of Legatum Homeopathicum project.
The creation of ONTNET will also heavily rely on existing ontologies or ontology-like structures that we plan to utilize to various degrees, such as:
WordNet - http://wordnet.princeton.edu/
Foundational Model of Anatomy - http://sig.biostr.washington.edu/projects/fm/AboutFM.html
Disease Ontology - http://do-wiki.nubic.northwestern.edu/do-wiki/index.php/Main_Page
Suggested Upper Merged Ontology (SUMO) - http://www.ontologyportal.org/
Estimated duration of Phase 2: 9 – 12 months
Estimated total costs of Phase 2: 20 000 – 30 000 EUR
Phase 3: Preparing TEXTBASE
The texts for inclusion in the TEXTBASE will be kindly donated by AEON GROUP (developer of Mercurius homeopathic software). The donated texts are in electronic form, formatted, sentence disambiguated, so only minor processing and formatting work should be necessary to prepare even large corpora for inclusion to OBJREP.
Estimated duration of Phase 3: 1 – 2 months
Estimated total costs of Phase 3: 3 000 – 5 000 EUR
Phase 4: Further development of ONTSOFT
Further development of ONTSOFT may run in parallel with the development of ONTNET. The additional functions to be implemented will cover tools and functions for seamless process of connecting TEXTBASE components (sentences) to ONTNET points.
Estimated duration of Phase 4: 2 – 3 months
Estimated total costs of Phase 4: 5 000 – 8 000 EUR
Phase 5: Mapping of TEXTBASE to ONTNET
Mapping of TEXTBASE to ONTNET is the core idea of object repertory. The duration and the costs of this phase are determined by the size of the TEXTBASE.
TEXTBASE consists of materia medica, which are provings (records of symptoms produced by a substance on healthy humans) and clinical symptoms – the source of information for homeopathic prescribing.
In order to achieve a useful result we consider implementing at least the following sources:
- Hahnemann, S., Materia Medica Pura
- Hahnemann, S., Chronic diseases (materia medica part)
- Allen, T.F., The Encyclopedia of Pure Materia Medica
- Hering C., The Guiding Symptoms of our Materia Medica
The total volume of these sources is about 40 000 standard pages (1800 characters per page). The estimated productivity (with a manual assignment of all the components of TEXTBASE sentence to ONTNET) is 60 – 90 min. per standard page.
Estimated duration of Phase 5 (with 20 people working 4 hours a day, manual approach): cca 2 – 3 years
Estimated total costs of Phase 5 (with an estimated wage of 10 EUR per hour, manual approach): 400 000 – 600 000 EUR
Given the high costs, a mixed approach utilizing advanced algorithms and a manual assignments, where the user would more or less just check the correctness of the assignment and make a correction from time to time. Since the effectiveness of algorithms in question can only be estimated, the time to process one standard page could be in the range of 20 – 40 minutes per page.
Estimated duration of Phase 5 (with 20 people working 4 hours a day, mixed approach): cca 6 – 12 months
Estimated costs of Phase 5 (with an estimated wage of 10 EUR per hour, mixed approach): 150 000 – 300 000 EUR for manual work
Estimated duration of development of advanced algorithms: 6 months
Estimated costs of development of advanced algorithms: 40 000 EUR
Phase 6: Further development of ONTNET
Further optional development ONTNET would consist of working on improving the integrity and relationships of ONTNET points with the aim of improving the total usability of the object repertory. In theory, this work is indefinite, therefore the range of such work can only be considered in face of practical considerations and when such point of the project development is reached.
Get involved
The estimated costs provided for each phase are calculated considering in-house development. In view of the proposed status of the results of the project (free for all), many parts of the project could be realized utilizing volunteer work, pretty much like any other open source project.
We are looking for volunteers willing to work on/support this project, especially
Developers for developing online apps (skills: ActionScript 3.0 for Flash and Flex, AJAX, Java, JavaScript, other languages suitable for online deployment),
Experts for working on ONTNET (skills: excellent understanding of English, great attention to detail, good understanding of homeopathy, anatomy, physiology, psychology and philosophy),
Worker bees for basic TEXTBASE mapping, typos corrections and other rudimentary tasks (skills: good understanding of English language, good attention to detail),
Communicators, Marketers, SEO Experts and PR Experts for improving our online presence, brand and audience reach, to attract talent and energy to this project
Last but not least – SPONSORS to provide funding that will allow this project to happen!
Anyone matching the desired skills and willing to join, please apply here now!
The more volunteers will join, the less money will be needed from the sponsors and the sooner we'll achieve the result!
Anyone donating 500 EUR and more – or having worked at least 200 hours on the project – is entitled to receive a free working version of Mercurius homeopathic software incorporating the Object Repertory (when it is implemented).
Licensing
As of this moment, we are looking either for sponsors or investors to finance the project. The source of financing of the project naturally influences the license for use of the resulting database.
The best scenario: we will accumulate enough money and volunteers to justify starting the project, with the result released in accordance with the terms of the Creative Commons Attribution-ShareAlike 3.0 Unported License (which allows commercial use). The results of the project will effectively become public domain, which is what we want.
Other scenario: we will find an investor willing to finance the project, use the result in any commercial way they like, for an agreed period of time and release the resulting database to public, when the agreed period has passed. In this case, all donations received specifically for this project will be offered to be returned to the donors.
Donate
If you wish to donate specifically for this project, please use the donation link below. For general purpose donations, please proceed here.

For direct bank transfer, please use the following banking information:
| Name on the Bank Account: | LEGATUM HOMEOPATHICUM |
|---|---|
| Foundation address: | Hrušková 28/A, 836 01 Bratislava, Slovakia |
| Bank Name: | FIO BANKA, A.S. |
| Bank Address: | Nám. SNP 21, 811 01 Bratislava, Slovakia |
| Bank Account number: | 2900308392 |
| BIC / SWIFT Code: | FIOZSKBAXXX |
| IBAN: | SK94 8330 0000 0029 0030 8392 |
In the message to the recipient, make sure to state PROJECT OBJREP or something similar indicating you wish to support this particular project.